Dbscan / 10. Unsupervised Learning — Data Science 0.1 documentation : In 2014, the algorithm was awarded the 'test of time' award at the leading data mining conference, kdd.
Dbscan / 10. Unsupervised Learning — Data Science 0.1 documentation : In 2014, the algorithm was awarded the 'test of time' award at the leading data mining conference, kdd.. The complexity of dbscan clustering algorithm. Rithm dbscan which discovers such clusters in a spatial database. For specified values of epsilon and minpts, the dbscan function implements the algorithm as follows: Metric is the process by which distance is calculated in. Dbscan is an algorithm for performing cluster analysis on your dataset.
The minimum number of points to form a dense region. It may be difficult for it to capture the clusters properly if the cluster density increases significantly. If a sparse matrix is provided, it will be converted into a sparse csr_matrix. Dbscan has many merits compared to other clustering methods such as kmeans. Ideally we want to be able to cut the tree at different places to select our clusters.
DBSCAN: Density-Based Clustering Essentials - Datanovia from www.datanovia.com The dbscan algorithm basically requires 2 parameters: Perform dbscan clustering from features, or distance matrix. This software is experimental, it supports only euclidean and manhattan distance measures ( why?) and it is not well optimized yet. Dbscan identifies 11 clusters and a set of noise points. If a neighborhood will include at least minpts it will be considered a dense region and will be part of a cluster. The complexity of dbscan clustering algorithm. Epsilon and minpoints to arrive at clusters. Definition of dbscan in the definitions.net dictionary.
Dbscan is an example of density based clustering algorithm.
The dbscan algorithm basically requires 2 parameters: The algorithm identifies three kinds of points: We then begin by picking an. Dbscan has many merits compared to other clustering methods such as kmeans. The complexity of dbscan clustering algorithm. In 1996 the algorithm finds dense areas and expands these recursively to find dense arbitrarily shaped clusters. And nowadays dbscan is one of the most popular cluster analysis techniques. Dbscan (density based spatial clustering of applications with noise) published by ester et. By contrast, any node that has k or more neighbors within the prescribed distance is said to be a core node. Section6 concludes with a summary and some directions for future research. If a neighborhood will include at least minpts it will be considered a dense region and will be part of a cluster. In 2014, the algorithm was awarded the 'test of time' award at the leading data mining conference, kdd. Ideally we want to be able to cut the tree at different places to select our clusters.
It was proposed by martin ester et al. Spark dbscan is an implementation of the dbscan clustering algorithm on top of apache spark.it also includes 2 simple tools which will help you choose parameters of the dbscan algorithm. Min_samples is the min points value. We then begin by picking an. This software is experimental, it supports only euclidean and manhattan distance measures ( why?) and it is not well optimized yet.
SlideWiki | undefined | DBSCAN: Sensitive to Parameters from fileservice.slidewiki.org Its main parameters are ε and minpts. The minimum number of points to form a dense region. Ideally we want to be able to cut the tree at different places to select our clusters. The algorithm also identifies the vehicle at the center of the set of points as a distinct cluster. Epsilon and minpoints to arrive at clusters. Scikit learn — demo of dbscan clustering algorithm. And nowadays dbscan is one of the most popular cluster analysis techniques. Dbscan simply leaves that as a (very unintuitive) parameter.
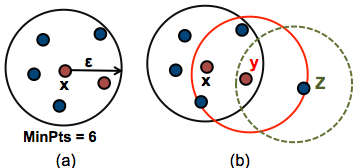
Ε is the radius of a neighborhood (a group of points that are close to each other).
The algorithm is proposed by: Worse, we really want to deal with variable density clusters and any choice of cut line is a choice of mutual reachability distance to cut at, and hence a single fixed density level. Information and translations of dbscan in the most comprehensive dictionary definitions resource on the web. Metric is the process by which distance is calculated in. The algorithm also identifies the vehicle at the center of the set of points as a distinct cluster. By contrast, any node that has k or more neighbors within the prescribed distance is said to be a core node. We then begin by picking an. It means that if the distance between two points is lower or equal to this value (eps), these points are considered neighbors. Dbscan identifies 11 clusters and a set of noise points. Definition of dbscan in the definitions.net dictionary. Dbscan identifies clusters in data sets by connecting (with directed edges) points (nodes) that lie less than a certain distance away (like in rgg s). Ε is the radius of a neighborhood (a group of points that are close to each other). It can identify any cluster of any shape.
The dbscan algorithm basically requires 2 parameters: Dbscan is an example of density based clustering algorithm. Dbscan identifies 11 clusters and a set of noise points. In kmeans, the number of cluster is a fixed number as a parameter feeding into kmeans model, which means the number of clusters does not change throughout the clustering process. It defines the neighborhood around a data point i.e.
Creation of a cluster by the DBSCAN algorithm. | Download ... from www.researchgate.net Dbscan identifies 11 clusters and a set of noise points. Specifies how close points should be to each other to be considered a part of a cluster. Epsilon and minpoints to arrive at clusters. Perform dbscan clustering from features, or distance matrix. And nowadays dbscan is one of the most popular cluster analysis techniques. If a neighborhood will include at least minpts it will be considered a dense region and will be part of a cluster. Section6 concludes with a summary and some directions for future research. Information and translations of dbscan in the most comprehensive dictionary definitions resource on the web.
If a neighborhood will include at least minpts it will be considered a dense region and will be part of a cluster.
C luster analysis is an important problem in data analysis. The algorithm also identifies the vehicle at the center of the set of points as a distinct cluster. The complexity of dbscan clustering algorithm. Perform dbscan clustering from features, or distance matrix. Metric is the process by which distance is calculated in. First we choose two parameters, a positive number epsilon and a natural number minpoints. Dbscan clustering algorithm is a very simple and powerful clustering algorithm in machine learning. For specified values of epsilon and minpts, the dbscan function implements the algorithm as follows: Definition of dbscan in the definitions.net dictionary. Ideally we want to be able to cut the tree at different places to select our clusters. It was proposed by martin ester et al. This software is experimental, it supports only euclidean and manhattan distance measures ( why?) and it is not well optimized yet. Core points, border points, and noise points 1.
In 2014, the algorithm was awarded the 'test of time' award at the leading data mining conference, kdd dbs. And nowadays dbscan is one of the most popular cluster analysis techniques.








0 Komentar